ByteCode
Instruction Set Summary
Bytecode
instruction format:
<opcode>
[<operand1> [<operand2>]]
·
An
instruction can have 0 or more operands
·
If
an operand is more than one byte in size, then it is stored in big-endian
order-high-order byte first. For example, an unsigned 16-bit index into the
local variables is stored as two unsigned bytes, byte1 and byte2, such that its
value is
(byte1<<8) | byte2
Ignoring
exceptions, the inner loop of a Java virtual machine interpreter is effectively
do {
fetch an opcode;
if (operands) fetch operands;
execute the action for the opcode;
}
while (there is more to
do);
Bytecode example for a method:
The spin
method simply spins around an empty for loop 100 times:
void spin() {
int i;
for (i = 0; i <
100; i++) {
; //
Loop body is empty
}
}
A compiler might
compile spin to
Method
void
spin()
0 iconst_0 // Push int
constant 0
1 istore_1
// Store into local variable
1 (i=0)
2 goto
8 // First time
through don't increment
5 iinc
1 1 // Increment local variable 1 by 1
(i++)
8 iload_1 // Push local variable 1 (i)
9 bipush
100 // Push int
constant 100
11 if_icmplt
5 // Compare and loop if
less than (i < 100)
14 return //
Return void when done
Load and Store Instructions
The load and
store instructions transfer values between the local variables and the operand
stack of a Java virtual machine frame:
·
Load
a local variable onto the operand stack:
iload, iload_<n>, lload, lload_<n>, fload, fload_<n>, dload, dload_<n>, aload, aload_<n>.
·
Store
a value from the operand stack into a local variable:
istore, istore_<n>, lstore,
lstore_<n>, fstore, fstore_<n>, dstore,
dstore_<n>, astore, astore_<n>.
·
Load
a constant onto the operand stack:
bipush, sipush, ldc, ldc_w, ldc2_w, aconst_null, iconst_m1, iconst_<i>, lconst_<l>,
fconst_<f>, dconst_<d>.
·
Gain
access to more local variables using a wider index, or to a larger immediate
operand:
wide.
Arithmetic Instructions
The arithmetic
instructions compute a result that is typically a function of two values on the
operand stack, pushing the result back on the operand stack. There are two main
kinds of arithmetic instructions: those operating on integer values and those
operating on floating-point values.
The arithmetic
instructions are as follows:
·
Add:
iadd, ladd, fadd, dadd.
·
Subtract:
isub, lsub, fsub, dsub.
·
Multiply:
imul, lmul, fmul, dmul.
·
Divide:
idiv, ldiv, fdiv, ddiv.
·
Remainder:
irem, lrem, frem, drem.
·
Negate:
ineg, lneg, fneg, dneg.
·
Shift:
ishl, ishr, iushr, lshl, lshr, lushr.
·
Bitwise
OR: ior, lor.
·
Bitwise
AND: iand, land.
·
Bitwise
exclusive OR: ixor, lxor.
·
Local
variable increment: iinc.
·
Comparison:
dcmpg, dcmpl, fcmpg, fcmpl, lcmp.
Type
Conversion Instructions
·
widening
numeric conversion instructions are i2l,
i2f, i2d, l2f, l2d, and f2d.
·
narrowing
numeric conversion instructions are i2b,
i2c, i2s, l2i, f2i, f2l,
d2i, d2l, and d2f.
Operand Stack Management Instructions
A number of
instructions are provided for the direct manipulation of the operand stack: pop, pop2,
dup, dup2, dup_x1, dup2_x1, dup_x2, dup2_x2, swap.
Object Creation and Manipulation
Although both
class instances and arrays are objects, the Java virtual machine creates and
manipulates class instances and arrays using distinct sets of instructions:
·
Create
a new class instance: new.
·
Create
a new array: newarray, anewarray, multianewarray.
·
Access
fields of classes (static fields, known as class variables): getstatic, putstatic.
·
Access
fields of class instances (known as instance variables): getfield, putfield
·
Load
an array component onto the operand stack: baload,
caload, saload, iaload, laload, faload, daload, aaload.
·
Store
a value from the operand stack as an array component: bastore, castore, sastore, iastore, lastore, fastore, dastore, aastore.
·
Get
the length of array: arraylength.
·
Check
properties of class instances or arrays: instanceof,
checkcast.
Operand Stack Management Instructions
A number of
instructions are provided for the direct manipulation of the operand stack: pop, pop2,
dup, dup2, dup_x1, dup2_x1, dup_x2, dup2_x2, swap.
The control
transfer instructions conditionally or unconditionally cause the Java virtual
machine to continue execution with an instruction other than the one following
the control transfer instruction. They are:
·
Conditional
branch: ifeq, iflt, ifle, ifne, ifgt, ifge, ifnull, ifnonnull, if_icmpeq, if_icmpne, if_icmplt, if_icmpgt, if_icmple, if_icmpge, if_acmpeq, if_acmpne.
·
Compound
conditional branch: tableswitch, lookupswitch.
·
Unconditional
branch: goto, goto_w, jsr, jsr_w, ret.
Method Invocation and Return Instructions
The following
four instructions invoke methods:
·
invokevirtual invokes an instance method of an object,
dispatching on the (virtual) type of the object. This is the normal method
dispatch in the Java programming language.
·
invokeinterface invokes a method that is implemented by
an interface, searching the methods implemented by the particular runtime
object to find the appropriate method.
·
invokespecial invokes an instance method requiring
special handling, whether an instance initialization method (§3.9), a private method, or a superclass method.
·
invokestatic invokes a class (static) method in a named class.
Return
Instructions: return, ireturn, lreturn, freturn , dreturn, and areturn.
Throwing Exceptions
An exception is
thrown programmatically using the athrow
instruction. Exceptions can also be thrown by various Java virtual machine
instructions if they detect an abnormal condition.
Jikes
RVM Code Generation for POWERPC:
What does the stacktrace look like when
machine code is generated from bytecode (.class file)?
VM_BaselineCompiler::genCode();
at line 305 returns VM_MachineCode
VM_BaselineCompiler::compile()
at line 195
VM_BaselineCompiler::compile(VM_Method;)
returns VM_CompiledMethod; at
line 181
VM_RuntimeCompilerInfrastructure::baselineCompile(LVM_Method;)
returns
VM_CompiledMethod;
at line 150
VM_RuntimeCompiler::
compile(LVM_Method;)returns VM_CompiledMethod; at
line 28
VM_Method::compile()
at line 428
VM::runClassInitializer(Ljava/lang/String;)
at line 266
VM::boot() at
line 150
VM_BaselineCompiler::genCode()
protected final VM_MachineCode genCode () {
emit_prologue();
for (bi=0; bi<bytecodes.length;) {
bytecodeMap[bi] =
asm.getMachineCodeIndex();
asm.resolveForwardReferences(bi);
biStart = bi;
int code = fetch1ByteUnsigned();
switch (code) {
case 0x00: /* nop */ {
if (shouldPrint)
asm.noteBytecode(biStart, "nop");
break;
}
case 0x01: /* aconst_null */ {
if (shouldPrint)
asm.noteBytecode(biStart, "aconst_null ");
emit_aconst_null();
break;
}
......
......
case 0x60: /* iadd */ {
if (shouldPrint)
asm.noteBytecode(biStart, "iadd");
emit_iadd();
break;
}
......
......
case 0xc9: /* jsr_w */ {
int offset =
fetch4BytesSigned();
int bTarget = biStart +
offset;
if (shouldPrint)
asm.noteBytecode(biStart, "jsr_w " + offset + " [" +
bTarget + "] ");
emit_jsr(bTarget);
break;
}
default:
VM.sysWrite("VM_Compiler:
unexpected bytecode: " + VM_Services.getHexString((int)code, false) +
"\n");
if (VM.VerifyAssertions)
VM.assert(VM.NOT_REACHED);
}
}
return
asm.finalizeMachineCode(bytecodeMap);
}
An Example of a bytecode to machinecode
generation method:
VM_Compiler::emit_iadd
/**
* Emit code to implement the iadd bytecode
*/
protected final void emit_iadd() {
asm.emitL
(T0, 0, SP); //LOAD // L T0, 0(SP) -- pop Top of
Stack into reg
asm.emitL
(T1, 4, SP); //LOAD // L T1, 4(SP) -- pop next Stack
elem into reg
asm.emitA
(T2, T1, T0); //ADD //
ADD T2, T1, T0 --- add two reg
asm.emitSTU(T2, 4, SP);
//STORE// STU T2, 4(SP) --- store result back to TOS
}
VM_Assembler::emitL
EmitL method
generates a load instruction of the form
L RT, D(RA). The exact machine
format of the instruction is as follows:
powerpc load instruction format:
bits
0-5 -> opcode(32)
6-10 -> RT(target register)
11-15 -> RA(source register)
16-31 -> D(displacement offset/immediate)
It starts with
Ltemplate that has the opcode(32) set in the 0-5 bits. Then it operates on it
using bit manipulation to put in RT, D, and RA
static final int Ltemplate
= 32<<26;
final void emitL (int RT,
int D, int RA) {
if (VM.VerifyAssertions) VM.assert(fits(D,
16));
INSTRUCTION mi = Ltemplate | RT<<21 | RA<<16 |
(D&0xFFFF);
if (VM.TraceAssembler)
asm(mIP, mi, "l", RT,
signedHex(D), RA);
mIP++;
mc.addInstruction(mi);
}
VM_Assembler::emitA
It generates an
add instruction of the form “Add RT, RA,
RB”. The exact machine
Format of this
instruction is as follows:
powerpc Add instruction format:
bits
0-5 -> opcode(31)
6-10 -> RT(target register)
11-15 -> RA(source register)
16-20 -> RB(source register)
21 -> overflow exception bit/0
22-30 -> 10
31 ->
Record flag bit
static
final int Atemplate = 31<<26 | 10<<1;
final void emitA (int RT,
int RA, int RB) {
INSTRUCTION mi = Atemplate | RT<<21 |
RA<<16 | RB<<11;
if (VM.TraceAssembler)
asm(mIP, mi, "a", RT, RA, RB);
mIP++;
mc.addInstruction(mi);
}
VM_Assembler::emitSTU
It generates an
STU instruction of the form 'STU RS,
D(RA)'
Instruction format for STU(store with
update)
bits
0-5 -> opcode(37)
6-10 -> RT(target register)
11-15 -> RA(source register)
16-31 -> D(displacement offset)
static final int
STUtemplate = 37<<26;
final void emitSTU (int RS,
int D, int RA) {
if (VM.VerifyAssertions) VM.assert(fits(D,
16));
INSTRUCTION mi = STUtemplate | RS<<21
| RA<<16 | (D&0xFFFF);
if (VM.TraceAssembler)
asm(mIP, mi, "stu", RS,
signedHex(D), RA);
mIP++;
mc.addInstruction(mi);
}
Discussions about Further Direction for Jalapeño/SV1
Project
Preliminary Decisions to Make towards the Machine Code
Generator
Lab 307
Cray Assembly Language (CAL) for Cray PVP Systems Reference Manual is the only available instruction manual for Cray PVP (Parallel Vector Processing) systems from CrayDoc (CRI’s official document distribution site). This is confirmed information through an e-mail response from CrayDoc Order Desk. “This manual does support the SV1 series systems. There are no other CAL manuals that are SV1 specific.”
[Figure 1] is a diagram drawn based on the compatibility information in an unofficial Cray FAQ in a newsgroup comp.unix.cray. It also mentioned that a generation has binary compatibility with the generation one step backward.
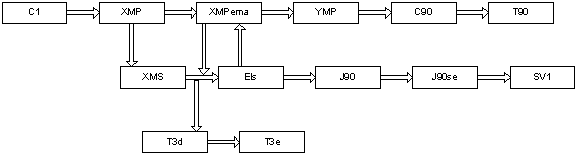
[Figure 1]
An educated guess from the information above is to adhere to SV1 specific documents as much as possible. For areas without SV1 specific information, we can refer to information for J90 since SV1 is binary compatible with J90se according to the information above.
The majority (about 80% in terms of the number of instruction) of them are common on Cray PVP systems. However, in-depth evaluation would be necessary about how significant the J90 specific instructions are for a generic executable image among a few hundred of machine instructions.
An alternative way to overcome those problems mentioned above is to emit Cray Assembly Codes instead of machine instructions and to use build-in assembler and linker. Additional benefit is Cray PVP systems supports CAL whichever physical layer they are. Besides, the intermediary assembly file would make the debugging process much easier. Please note that it is not though to be feasible to debug the Cray executable of the boot-image (Target JVM we build that runs on Cray).
In fact Cray PVP systems do have pass and breakpoint instructions. However it would require much more work to implement debugging feature with the binary file because the boot-image is a mapped direct-translation of Java Bytecode.
There is very little information available on Cray CPU Architecture. We are identifying the architectural structures by analyzing machine instruction i.e. addressing model, pragmatic usage of registers, system calls
For the next steps, comparison seem to be necessary between Java Bytecode instructions and Cray machine instructions or Cray Assembly Language depending on which one we choose. At the same time, more research on native Cray representations of native Java types on Cray should be accompanied along with the comparison.